Preview
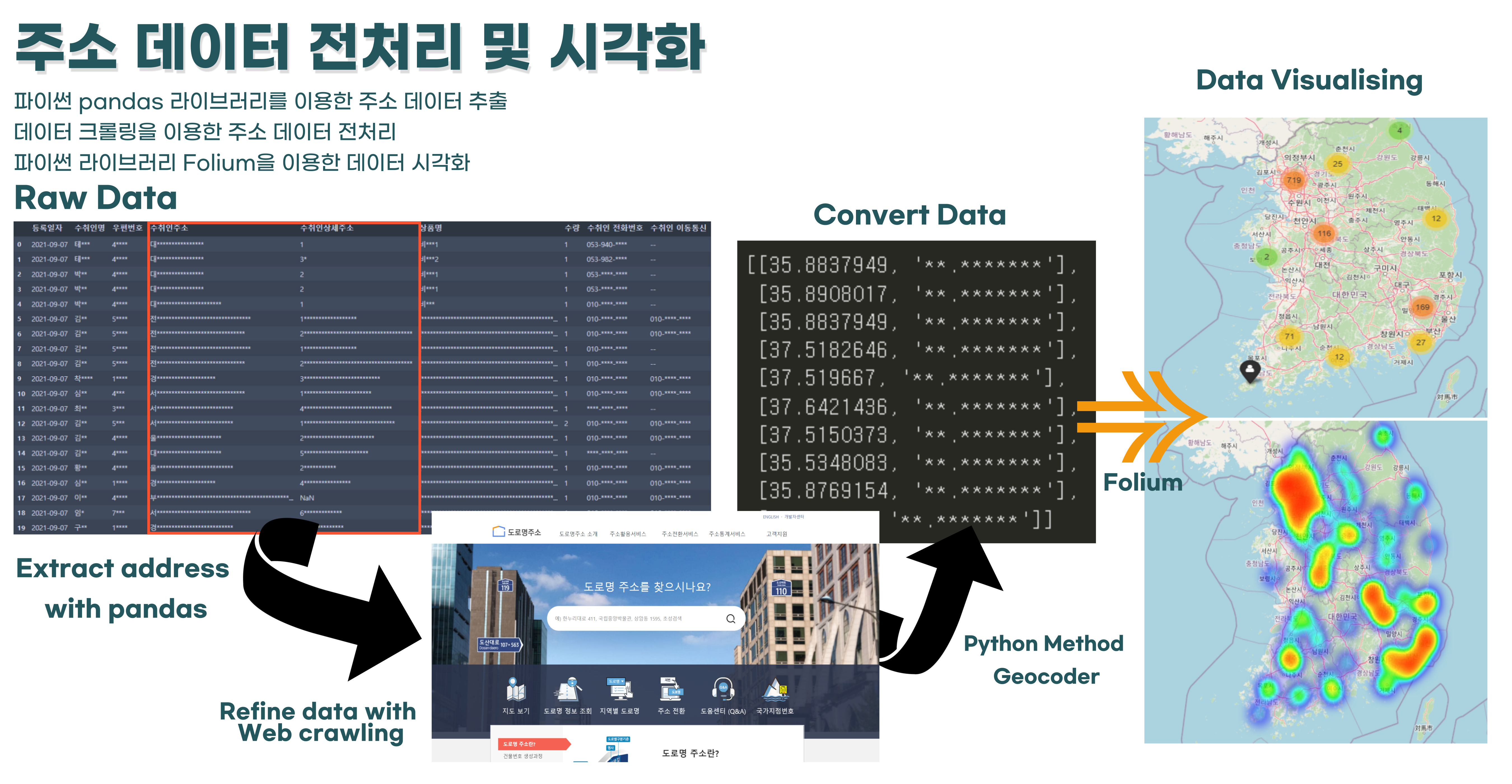
Abstract
GOAL : 오프라인 매장 입지 선정을 위한 국내 고객 위치 분포 조사
Benefit : 오프라인 판매 매장 입지 선정을 위한 참고 자료로 이용
TASK : 고객 주소 데이터를 가공하여 히트맵으로 시각화해 제공하기
Solution Method
- python Pandas를 이용한 고객 데이터 EDA
- 데이터 크롤링을 통한 주소 가공
- Folium 메서드를 이용한 시각화 (MarkerCluster, Heatmap)
Tools
- Google colab pro (GPU + RAM)
- Anaconda Jupyter Notebook
Background
알바 중인 온라인 비타민 판매 회사에서 최근 회사 규모가 커짐에 따라 오프라인 판매 직영점을 오픈하려고 한다. 하지만 다양한 지역에서 주문이 들어오는 탓에 어떤 지역에 매장을 개설해야 할지 고민인 상태였다. 따라서 고객 데이터 분석을 통해 전국의 고객 분포를 파악하고, 매장 입지 선정에 도움을 주고자 한다.
또한, 주문 고객의 위치 분포를 파악, 추적함으로써 지역별 맞춤 서비스 및 프로모션 제공에도 기여할 수 있을 것으로 기대된다.
1. Data 불러오기
2021년 4/4분기 고객 데이터를 받아 프로젝트를 진행했다.
[Input]
file_path = '/content/drive/MyDrive/Colab_Notebooks/private_project/purchase.xlsx'
df = pd.read_excel(file_path)
먼저, 원본 데이터의 고객정보를 보호하기 위해 출력 시 데이터를 일부 숨겨야 할 필요가 있다고 판단되었다. 이에 고객의 정보가 특정될 만한 이름, 우편번호, 주소, 전화번호, 상품명 등은 모두 가려서 출력하는 함수를 제작했다.
[Input]
# 보안을 위해 프린트 모자이크 함수 만들기
# 프린트 할때만 그렇게 나와야함 - 실제로 다 바뀌면 안됨
# 수취인명 : 김**
# 우편번호 : 4****
# 수취인 주소 : 대***************
# 수취인 상세주소 : 1*****
# 상품명 : 비****
# 수취인 전화번호 : 053-954-****
# 수취인 이동통신 : 010-****-****
def secure_print(data):
df1 = data.copy()
###원본 데이터 출력 모자이크
try:
df1['수취인명'] = df1['수취인명'].str.replace('(?<=.)(.)', r'*')
except:
pass
try:
df1['우편번호'] = df1['우편번호'].apply(str)
df1['우편번호'] = df1['우편번호'].str.replace('(?<=.)(.)', r'*')
except:
pass
try:
df1['수취인주소'] = df1['수취인주소'].str.replace('(?<=.)(.)', r'**')
except:
pass
try:
df1['수취인상세주소'] = df1['수취인상세주소'].str.replace('(?<=.())(.)', r'*')
except:
pass
try:
df1['상품명'] = df1['상품명'].str.replace('(?<=.)(.)(.)', r'***')
except:
pass
try:
df1['수취인 전화번호'] = df1['수취인 전화번호'].str.replace('\d\d\d\d', r'****')
except:
pass
try:
df1['수취인 이동통신'] = df1['수취인 이동통신'].str.replace('\d\d\d\d', r'****')
except:
pass
###변형 데이터 출력 모자이크(추가된 컬럼 값 - address, number)
try:
df1['address'] = df1['address'].str.replace('(?<=.())(.)', r'*')
except:
pass
try:
df1['number'] = df1['number'].str.replace('\d\d\d\d', r'****')
except:
pass
return df1해당 함수를 통해 출력되는 데이터의 형태는 다음과 같다.
[Input]
secure_print(df)[:20][Output]

2. Data 파악
먼저 전달받은 데이터 셋의 기본 크기와 데이터의 기본 골자를 파악해 보았다.
Non-Null count를 살펴보니 몇몇 column에서 결측치가 존재함을 발견했다. 이에 결측치를 뽑아봤다.
[Input]
df.info()[Output]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1600 entries, 0 to 1599
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 등록일자 1600 non-null object
1 수취인명 1600 non-null object
2 우편번호 1600 non-null int64
3 수취인주소 1600 non-null object
4 수취인상세주소 1586 non-null object
5 상품명 1600 non-null object
6 수량 1600 non-null int64
7 수취인 전화번호 1383 non-null object
8 수취인 이동통신 1600 non-null object
dtypes: int64(2), object(7)
memory usage: 112.6+ KB
몇 가지 열에서 결측치가 발생한 것으로 추정, 열 별로 결측치 파악을 실시했다.
[Input]
df.isna().sum()[Output]
등록일자 0
수취인명 0
우편번호 0
수취인주소 0
수취인상세주소 14
상품명 0
수량 0
수취인 전화번호 217
수취인 이동통신 0
dtype: int64'수취인 상세주소'와 '수취인 전화번호'에서 결측치 발생
- 수취인 전화번호 결측치 - 고객의 전화번호는 하나만 있으면 된다. 수취인 이동통신 결측치가 0이므로 수취인 전화번호는 삭제.
- 수취인 상세주소의 결측치 - 수취인 주소에 이미 다 기입된 경우 多, 결측 값을 임의로 채우지 말고, 수취인 주소 + 수취인 상세주소를 합친 최종 주소 열 만들고, 기존 '수취인 주소', '수취인 상세주소' 열은 삭제
[Input]
# columns 삭제 - 수취인 전화번호 삭제
df_ex1 = df.drop(['수취인 전화번호'], axis = 1)
# df_ex1
secure_print(df_ex1)[Output]

수취인 이동전화에는 결측치가 없는 줄 알았지만, 해당 데이터셋은 이동통신이 없을 때 NaN값이 아닌 '--'을 기입해 결측치 판단을 못하게 막고 있었다. --를 nan값으로 바꿔준 뒤 다시 NaN값을 파악해 보기로 했다.
[Input]
# -- -> NaN
df_ex2 = df.replace('--', np.NaN)
df_ex2.isnull().sum()[Output]
등록일자 0
수취인명 0
우편번호 0
수취인주소 0
수취인상세주소 14
상품명 0
수량 0
수취인 전화번호 957
수취인 이동통신 70
dtype: int64다시 NaN값을 파악해 보니 전화번호 및 이동통신에 모두 nan값이 많이 존재했다. 전화번호, 이동통신 두 값 다 nan값이 있는 경우를 조사해보자.
[Input]
# 전화번호 정보가 없는 고객 추출
df_ex3 = df_ex2.notnull() #nan = false / value = true
condition = (df_ex3['수취인 전화번호'] == False) & (df_ex3['수취인 이동통신'] == False) #두 부분의 값이 모두 false일때, 즉 nan일때
nan_index = list(df_ex3[condition].index) # 해당 조건을 만족하는 행의 index 뽑기
nan_index
weird = df_ex2.iloc[nan_index] # 뽑은 인덱스로 원데이터에서 뽑기
secure_print(weird)[Output]
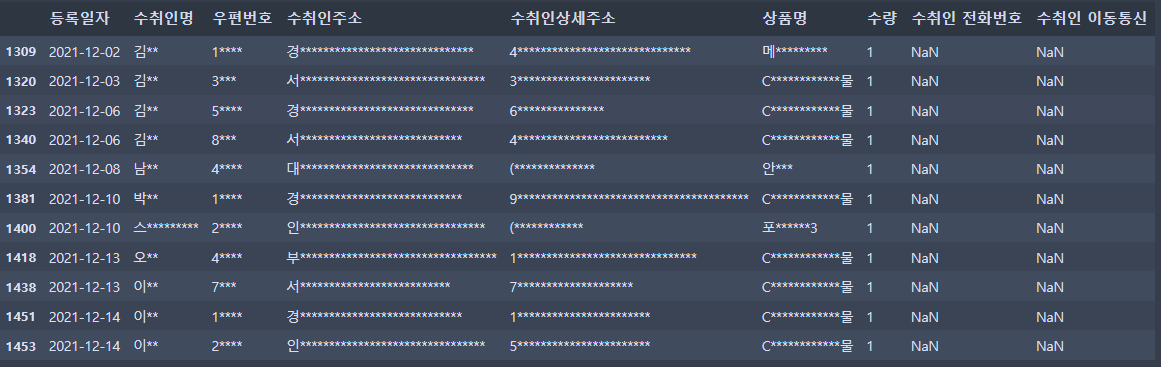
분석 결과 총 11명에서 전화번호 데이터가 없는 것으로 밝혀졌다.
고객들의 상품명을 보니 9명이 크리스마스 선물로, 서비스 제품 제공 데이터라는 것을 파악할 수 있었다. 해당 회사는 크리스마스 때마다 vip고객에게 서비스 상품을 발송하는데, 이러한 과정에서 굳이 전화번호를 기입하지 않은 것으로 보인다. 나머지 2번의 경우 각각 치약 3, 안내문이 적혀있는데 사측 확인 결과 샘플 제품 발송으로 확인했다.
즉, 전화번호가 없는 결측치는 모두 이벤트성 제품 발송이다. 따라서 해당 행들은 실제 구매와 관련이 없으므로 삭제해 주자.
3. Data cleansing
3-1. 주소열 합치기
가장 먼저, '수취인 주소'와 '수취인 상세주소' 칼럼을 병합한다. 이후 기존 주소 열은 삭제한다.
수취인 주소에는 시/군/구/로, 상세주소에는 지번과 건물 이름, 호수 등이 주로 기입되어 있다. 그러나 특정 고객들에서 '수취인 주소'에 모든 주소를 기입하고 상세주소는 비워두거나, 도로명 주소가 아닌 구 주소로 기입하는 등의 예외 경우가 많아 두 열 값을 통합해 하나의 온전한 주소 값을 받고, 이 값을 다시 정제한다.
[Input]
# 주솟값 합치기
df_ex2['address'] = df_ex2['수취인주소'] + " " + df_ex2['수취인상세주소'].fillna('') #nan값이 있는 경우, 합치면 nan값만 반환하기 때문에 nan값일 경우 다른 문자로 치환해 줘야함
# 기존 열 삭제
df_ex2 = df_ex2.drop(['수취인주소', '수취인상세주소'], axis = 1)
# df_ex2
secure_print(df_ex2)[Output]
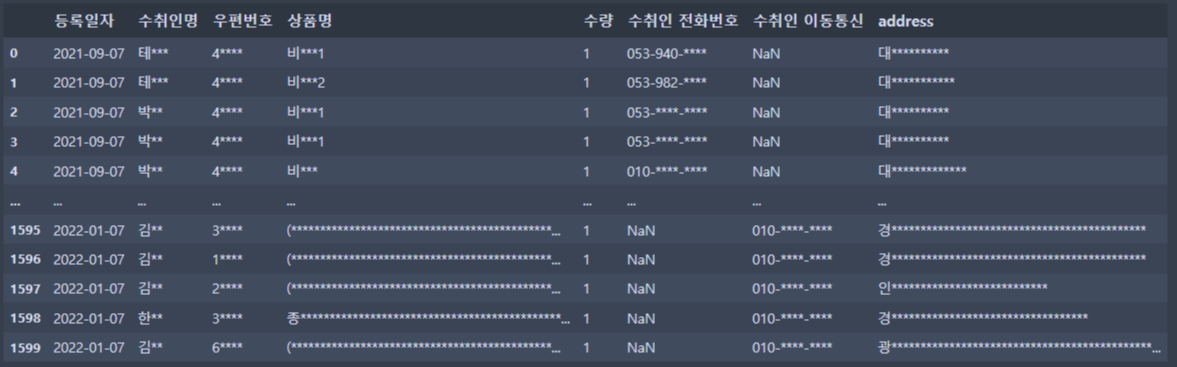
3-2. 전화번호 열 합치기
이제 고객 전화번호를 합쳐 새로운 대표 전화번호 열을 만든다.
고객 전화번호는 대표 번호 하나만 존재하면 충분하다. 따라서 먼저 핸드폰 번호 정보가 있는지를 파악하여, 있다면 집전화가 있어도 핸드폰 번호를 할당하고, 집전화 정보만 존재하는 경우에만 집전화번호를 할당한다.
[Input]
#number 항 만들기
#sudo code
#대표 전화번호 col 만들기
# 집전화 핸드폰 둘 다 있는 경우/ 집전화만 있는 경우/ 휴대폰만 있는 경우 / (둘다 없는 경우는 삭제함)
# 둘다 있다? -> 핸드폰 번호 가져오기
# 집전화만 있다? -> 집전화 번호 가져오기
# 핸드폰 번호만 있다? -? 핸드폰 번호 가져오기
# if 휴대전화 존재 -> 휴대전전화 데이터 가져오기
# else -> 집전화 데이터 가져오기
# nan값을 식으로 표현할 수가 없어서, 0으로 nan을 치환 ->> 여기서 3시간 걸림 (nan값을 조건식에서 표현하는 방법을 모르겠음)
df_ex2.fillna(0, inplace = True)
# 만약 이동통신 값이 0이 아니면(즉 존재하면) 이동통신 값 받기,
#그렇지 않으면(이동통신 번호가 없는경우, 즉 전화번호만 있는 경우) 수취인 전화번호 받기
df_ex2['number'] = np.where(df_ex2['수취인 이동통신'] != 0, df_ex2['수취인 이동통신'], df_ex2['수취인 전화번호'])
# df_ex2
secure_print(df_ex2)
[Output]

이 부분에서 중요한 점은, Nan값이 온재하는 경우 넘파이에서 지원하는 비교 연산이 상당히 쉽지 않다는 점이었다. 이를 해결하기 위해 다양한 방식으로 로직을 짜 보았으나, 다 잘 되지 않아 아예 Nan값을 모두 0으로 치환한 후 where 함수를 이용해 할당했다.
3-3. 이벤트성 고객 데이터 삭제
기존에 파악한 11개의 이벤트성 기록을 nan_index를 이용해 삭제해 준다
[Input]
#nan index(크리스마스 발송, 샘플 발송 삭제)
df_ex2 = df_ex2.drop(nan_index)
# df_ex2
secure_print(df_ex2)
[Output]

여기서 주의할 점은, 삭제 후 인덱스를 초기화해 주어야 한다는 점이다. 삭제된 11개의 데이터로 인해 전체 데이터의 길이는 줄었으나, 인덱싱은 그대로 1599에서 끝난다. 이 때문에 이후 작업에서 반복문을 돌릴 때 Key-error가 발생할 수 있다. 따라서 삭제 후엔 반드시 인덱싱 초기화를 통해 데이터를 정리해 주어야 한다.
[Input]
# 앞선 열 삭제로 인한 인덱싱 누락 처리
df_ex2[1300:1310] # 1309행이 지워져 있음 - key error 1309에서 확인함
df_ex2 # 1589 rows × 7 columns, 근데 마지막이 1599니까, 인덱스 초기화 필요해 보임 - 앞서 지웠던 11개 컬럼들때문에 영향 생긴듯
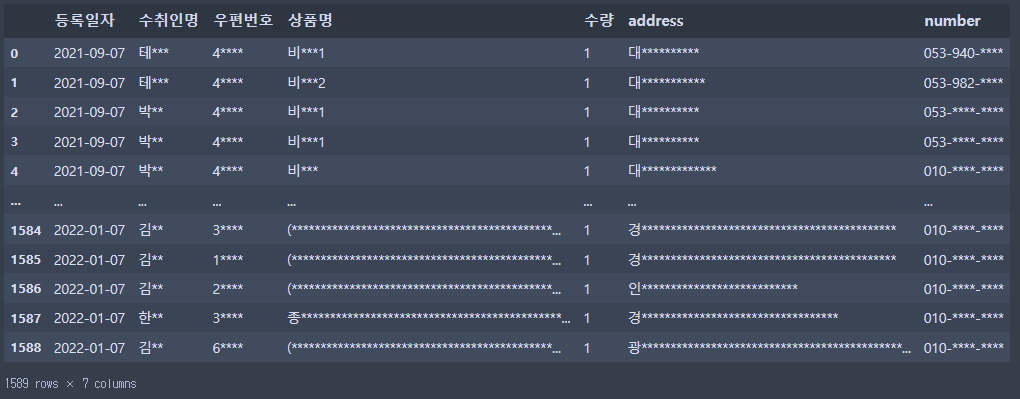
df_ex2 = df_ex2.reset_index(drop = True)
# df_ex2
secure_print(df_ex2)
[Output]
3-3. 주소 열 값 정규화
주 솟값을 이용한 시각화를 위해 해당 데이터에서 address만 추출하여 사용한다.
[Input]
#시각화에 필요한 address 정보만 추출
df_adress = df_ex2['address']
# df_adress
#출력용
df_adress_print = df_adress.str.replace('(?<=.())(.)', r'*')
df_adress_print[Output]
0 대**********
1 대***********
2 대**********
3 대**********
4 대*************
...
1584 경********************************************
1585 경********************************************
1586 인***************************
1587 경**********************************
1588 광*********************************************...
Name: address, Length: 1589, dtype: object온전한 주소 값만 산출된 Series를 가져왔다.
3-3-1. 문제 상황
주소 데이터를 위도/경도 값으로 변환해 Folium 라이브러리를 이용한 시각화를 진행하고자 한다.
구글링 결과 상세 주소를 위도, 경도 값으로 변환해주는 코드가 있어 이용해 보기로 했다. 이를 위해선 먼저 주소나 우편번호를 위도, 경도 값으로 변경하는 작업이 필요하다.
https://github.com/yjw5344/Geocoder-Python
3-3-1. 정규표현식으로 주소 값 전처리
해당 코드가 필요로 하는 인풋 형태로 데이터를 가공한다. Python 정규표현식을 이용해 주소를 가공해 보았다
[Input]
# 정규표현식으로 식 처리하기
#마지막에 호수 정보 삭제 - 띄어쓰기 기준 6음절 이후 삭제 (지역/구/로/도로주소/숫자)
import re
df_adress_refine = df_adress.copy()
adress_len = len(df_adress_refine)
# 주소 데이터 깔끔하게 다듬기 1 - 띄어쓰기 기준 5음절 이후 삭제
for i in range(adress_len): # adress_len = 1590
a = df_adress_refine[i].split(' ')
#if 마지막 음절이 '-로' 로 끝나면 6음절까지 합치기/ 그외에는 5음절까지 합치기
print(a) # 형태소 리스트 뽑기
regex = re.compile('\로') #-로로 끝
for k in a:
print(k)
print(regex.findall(k))
if regex.findall(a[-1]) == ['$로']:
df_adress_refine[i] = " ".join(a[0:5])
print('done')
else:
df_adress_refine[i] = " ".join(a[0:4])
# 주소 데이터 깔끔하게 다듬기 2 - 괄호 있는 뒷부분은 다 지우자
for i in range(adress_len):
a = df_adress_refine[i].split('(') #괄호 기준으로 나누자
df_adress_refine[i] = a[0] # 첫 번째 괄호 나오기 전 문자열을 취하자
#특수문자제거
#샘플
df_adress_refine[95] #엑셀에선 96
df_adress_refine.tail()
정제 주소 엑셀로 저장
df_adress_refine.to_excel('/content/drive/MyDrive/Colab_Notebooks/private_project/healthy_like/address_refine.xlsx', encoding='cp949', index = False, header = False)
# 대실패 ㅎ
- 정규화 처리를 통한 주소 데이터 손질 결과(실패)
- 먼저 기본적으로 처리하고자 했던 부분은 띄어쓰기를 기준으로 음절을 나누어 길이를 절삭 시도
- 주소 데이터는 기본적으로 (지역/구/도로명/건물번호/ 그 외 상세주소 )로 나뉜다고 가정, 4음절까지 절삭해서 해결하고자 함
- 하지만 슬프게도 데이터 중엔 띄어쓰기가 안되어있는 경우, 구 주소로 기입되어 있는 경우도 존재하여 더 많은 조건식이 필요
- 따라서 마지막 음절이 '-로'로 끝나는 경우, 건물번호가 누락되었다고 가정, 그 경우만 5음절로 절삭하는 코드를 짜다가 실패 : 너무 복잡함...
- 생각한 우회책
- 도로명 주소로 모든 주소를 바꾸고, 모두 같은 양식으로 통일해야 한다고 여겨짐.
- 크롤링을 이용해 도로명주소 찾기 사이트에 모든 행의 주소 값을 넣어 나오는 결괏값(정제되고 일괄적인 주소)으로 geocode를 돌려보면 어떨까? -> 시도해 보자!
3-3-2. 웹 크롤링을 통한 주소 값 전처리
웹 크롤러를 이용해 주소 찾기 사이트에 접근, 가지고 있는 주소 값을 넣어서 검색된 검색 결과를 수집해 정형화된 주소 값을 얻는 방식을 시도했다. Colab에서 크롤링을 하기 위해서는 드라이버 설치 및 환경설정 변경 등이 필요해서, 로컬의 아나콘다 - Jupyter Notebook을 이용하여 크롤링을 진행한 뒤, 엑셀 파일만 가져와 다시 진행하기로 했다.
[Input]
#헬시라이크 주소데이터 손질 코드
#노이즈가 많은 주소데이터를 하나의 양식으로 통일시키기 위해 고안
#전체 workflow
#크롤링- 매크로를 통하여 노이즈가 낀 주소를 주소찾기 사이트에서 검색
#거기서 나온 도로명 주소값을 가져오기
#맨 뒤에 괄호 부분은 제거
#geocoder를 사용해 좌표를 뽑아내기
#코랩에서 크롤링이 불가한 관계로 로컬 주피터에서 실행
#실행시 vscode가 아닌 anaconda jupiter로 실행
#sudo code
#refine_list = []
#브라우저 열기
#사진찍고 저장
#도로명 주소 사이터 들어가기
#for i in df_adress 인자 하나씩 꺼내서
#검색창에 i 넣기
#검색 누르기
#print 도로명 주소 str값 - 궁금하자누
#refine_aderss = 도로명 주소 str값
#refine_list.append(refine_adress)
###############################
#작업환경 구축
!pip install geocoder
!pip install geopy
!pip install selenium
!pip install chromedriver-autoinstaller
import chromedriver_autoinstaller
from selenium import webdriver
from bs4 import BeautifulSoup #html에서 원하는 내용을 찾아주는 라이브러리
from geopy.geocoders import Nominatim
import time
import pandas as pd
import random
###############################
#파일 가져오기
df = pd.read_excel('address.xlsx', header = None)[0]
geo_local = Nominatim(user_agent='South Korea')
# 위도, 경도 반환하는 함수
def geocoding(address):
geo = geo_local.geocode(address)
x_y = [geo.latitude, geo.longitude]
return x_y
#괄호 이후 절삭하는 함수
def delete_detail(str):
a = str.split('(') #괄호 기준으로 나누고
str = a[0]
return str
# 도로명 주소 찾기 start!
chromedriver_autoinstaller.install() # chromedriver 최신버전설치 - 무조건 먼저 해주자
browser = webdriver.Chrome() # 브라우저 열기 - in local or jupyiter
url = 'https://www.juso.go.kr/openIndexPage.do'
browser.get(url) #해당 url 열기 - 브라우저 안열고 실행하면 오류남
lan_log = []
failed_address = []
for i in df:
# 정보 저장
refine_data = delete_detail(i) # 검색하기 좋게 괄호 뒤는 제거
print('검색할 주소 : ',i)
soup = BeautifulSoup(browser.page_source, "html.parser")
#검색창에 문자 넣고 검색
word_part = browser.find_elements_by_css_selector('#inputSearchAddr')[0] #검색창 위치
word_part.clear() #검색창 초기화, selenim형식의 특정위치로 나옴
word_part.send_keys(refine_data) #검색창에 주솟값 넣기
#POP UP창 있으면 지우기
try:
time.sleep(1.5)
ad_btn = browser.find_elements_by_css_selector('#qustnrDiv > div.closeWrap > a > span')[0]
ad_btn.click()
except:
pass
#검색 버튼 누르기
go_btn = browser.find_elements_by_css_selector('.btn_search')[0]# 검색 버튼 찾기
go_btn.click()
#사람처럼 보이도록 랜덤하게 쉬는 시간 변경해주기
time.sleep( random.uniform(1,4) ) # 2~4초 사이 랜덤한 시간으로 쉬자 - 나 사람이에요~
#### 검색한 창으로 들어감
soup = BeautifulSoup(browser.page_source, "html.parser") #저장하기
address = soup.select('div#list1 > div.subejct_1 > .roadNameText')# 도로명 주소값찾기
#검색한 결과가 있으면, 정제후 저장 / 없다면(즉 오류가 난다면) 넘어가자
try:
address = address[0].text #도로명 주소값만 가져오기
print('홈피에서 추출한 도로명주소 :',address)
#ad_ex에서 괄호 빼주기
temp = address.split('(')
address = temp[0] #str 값
print('정제후 geocoder에 들어가는 주소str: ', address, "\n")
###### geocoder 이용해서 좌표값 뽑아내기######
####### 도로명주소 위도 경도 값으로 바꿔주기 ######
address_location = geocoding(address)
#리스트에 넣기
lan_log.append(address_location)
print('주솟값 변환 완료', '\n\n')
except:
print('주솟값 변환 실패 - 직접 변경 요망', '\n\n')
failed_address.append(i)
pass
#뒤로가기 버튼 누르기
go_back = browser.find_elements_by_css_selector('h1 > a.logo')[0]# 검색 버튼 찾기
go_back.click() #홈 버튼 누르기
#####위,경도 값 각각 기존 데이터에 붙이기#####
#반환한 좌표 리스트를 dataframe으로 변환
lan_log = pd.DataFrame(lan_log, columns = ['latitude', 'longtitude'])
# 파일 저장
PATH = 'C:/Users/USER/data_crawling/lan_log.xlsx'
lan_log.to_excel(PATH, encoding='cp949', index = False)
#계속 하나씩 걸리네 ㅜ
[Output]
주솟값 변환 완료해당 크롤링을 통한 전처리로 총 1170개의 데이터가 위도/경도 값으로 변환되었고, 정제되지 않은 데이터, 즉 검색 결과가 없는 데이터가 417개가량 발생했다. 이 데이터는 falied_lan_log.xlsx 파일에 저장해 다른 방식의 전처리를 진행하고자 한다.
len(lan_log)
##1170
len(failed_address)
##417#처리 안된 값들 데이터프레임화 하고, 저장
failed_address = pd.DataFrame(failed_address, columns = ['address'])
PATH = 'C:/Users/USER/data_crawling/failed_lan_log.xlsx'
failed_address.to_excel(PATH, encoding='cp949', index = False)4. 구매 고객 분포 Visualising
이제 만들어진 위도/경도 파일을 이용해 시각화를 실시한다.
#시각화 환경 구축
!pip install geopandas
import requests
import json
import os
import math
import time
import pandas as pd
import numpy as np
import geopandas as gpd
import folium
import matplotlib.pyplot as plt
from shapely.geometry import mapping, shape, Point, Polygon, LineString
from folium import plugins
from folium.plugins import MarkerCluster, HeatMap
print('슝~')
import pandas
import geopandas
import folium4-1. MarkerCluster Visualising
먼저, markercluster로 시각화를 진행했다.
[Input]
# 위도는 36.832547072453664, 경도는 127.8101464367857 입니다
# 한국 center 찾기
center = [36.832, 127.810]
map = folium.Map(
location=center,
zoom_start=8,
)
print('슝~')
map# MarkerCluster 객체 만들기
marker_cluster = MarkerCluster().add_to(map)
#maker 객체 추가
for _, row in lan_log.iterrows():
try:
folium.Marker(
location=[row["latitude"], row["longtitude"]], # 좌표
# popup=row["customer"], # 클릭시 표시될 popup 내용
icon=folium.Icon(color="black", icon="user", prefix="fa")
).add_to(marker_cluster)
except:
pass
map[Output]

4-2. Heatmap Visualising
마지막으로 히트맵을 이용한 시각화를 진행했다. 히트맵 모듈에서 원하는 인풋은 리스트이므로 리스트 형태로 데이터 프레임을 바꾸어준다.
#lan_log를 list형태로 바꾸자
lan_log = lan_log.values.tolist()
[Input]
#lan_log 보안 출력용
fake_lan_log = lan_log[:10]
fake_print = []
for fake1, fake2 in fake_lan_log:
fake = [fake1, '**.*******']
fake_print.append(fake)
fake_print
[Output]
[[35.8837949, '**.*******'],
[35.8908017, '**.*******'],
[35.8837949, '**.*******'],
[37.5182646, '**.*******'],
[37.519667, '**.*******'],
[37.6421436, '**.*******'],
[37.5150373, '**.*******'],
[35.5348083, '**.*******'],
[35.8769154, '**.*******'],
[35.57532, '**.*******']]다음은 시각화된 히트맵이다.
[Input]
# 위도는 36.832547072453664, 경도는 127.8101464367857 입니다
# 한국 center 찾기
center = [36.832, 127.810]
map2 = folium.Map(
location=center,
zoom_start=8,
)
#make a heatmap here
map2 = map2.add_child(plugins.HeatMap(lan_log, radius = 20))
map2[Output]

5. Review
해당 프로젝트를 통해 pandas, web crawling, Folium 등 다양한 라이브러리들을 접하고, 사용해 볼 수 있어 좋았다. 실제 데이터로 진행을 해 보니 kaggle에서 제공하는 데이터처럼 깨끗하고 잘 정리된 데이터는 잘 존재하지 않는구나, 라는 생각이 든다. 노이즈가 가득한 원 데이터를 잘 가공하는 능력이 데이터 분석 업무에서 가히 필수적이라는 걸 체감했다.
또 주소 데이터처럼 전처리하기 까다로운 데이터를 정제하기 위해 이 방법, 저 방법 시도해 본 것이 사고력, 및 코딩 능력 향상에 도움이 많이 되었다. 해당 프로젝트를 하면서 크롤링과 시각화 스터디를 진행했는데, 스터디 때 배웠던 기법들을 바로 실전에 적용할 수 있어 더 빠르게 학습할 수 있었다.
진행하며 막히는 부분이 셀 수 없이 많았는데, 그때마다 스터디나 구글링을 통해 문제를 해결해 나가는 것이 즐거웠고, 해결했을 때의 쾌감이 이루 말할 수 없었다.
해당 프로젝트의 한계는 전처리에 실패한 400여 개의 데이터를 결과에 반영하지 못했다는 점이다. 약 25%를 누락시킨 셈인데, 실패한 데이터 셋을 저장해 두었으니 카카오 API나 다음 API 등을 이용하여 전처리를 마저 진행해 추가하는 것을 생각하고 있다. 또 현재 작년 9월부터 1월까지의 5개월간의 데이터만으로 실시했는데, 구매가 진행됨에 따라 자동으로 히트맵과 마커 클러스터가 지속적으로 갱신되게끔 구현하면 더 유용한 분석 툴이 될 것 같다. MLOps 지식을 갖추게 되면 도전해 보자.
'프로젝트 기록부' 카테고리의 다른 글
| 개인 프로젝트 04. - 강아지 VS 고양이 사진 분류 AI 웹 서비스 개발 (0) | 2023.05.18 |
|---|---|
| 개인 프로젝트 03. - 웹 서비스 개발일지 (0) | 2023.02.08 |
| 개인프로젝트 02. - 캐주얼 웹 게임 개발 (0) | 2023.02.07 |



댓글