자연어 처리 분야에 잘 이용되는 embedding, recurrent layer에 대해 알아보자
단어의 희소 표현(Sparse Representation)
단어의 분산 표현(Distributed Representation)
분포 가설(distribution hypothesis)? : 유사한 맥락에서 나타나는 단어는 그 의미도 비슷하다
맥락? - 좌우에 출현하는 다른 단어들
- 분포 가설에 따라 모든 단어를 고정 차원 (예를 들어 256차원)의 벡터로 표현
- 어떤 차원이 특정한 의미를 가진다고 가정하진 않음.
- 유사한 맥락에 나타난 단어들끼리는 두 단어 벡터 사이의 거리를 가깝게 하고, 그렇지 않은 단어들끼리는 멀어지도록 조금씩 조정 [이렇게 얻어지는 단어 벡터 : 분산 표현(Distributed Representation)]
- 분산 표현을 사용하면 희소 표현과는 다르게 단어 간의 유사도를 계산으로 구할 수 있음!
Q1. Embedding 레이어는 신경망 훈련 도중에 업데이트되는 것이 일반적이지만, Embedding 레이어만을 훈련하기 위한 방법도 있다. 무엇이 있는가?
A1. ELMo, Word2Vec, Glove, FastText 등이 있다.
Embedding 레이어
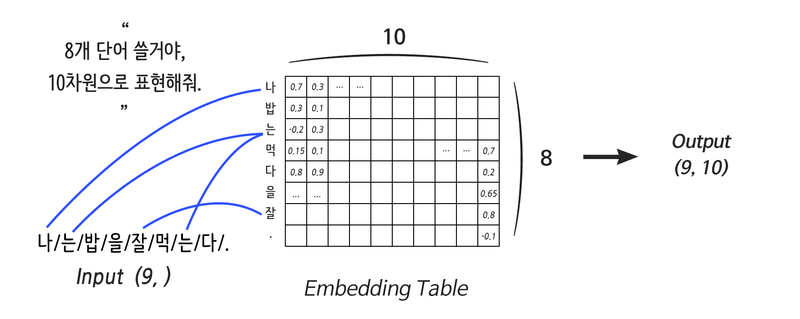
- 단어의 갯수 - 사용할 단어의 갯수
- 단어의 깊이 - 각 단어의 표현 깊이 - 분산 표현 정도.
- 임베딩 사이즈 - 단어갯수 x 단어 깊이
- Lookup Table - 임베딩 테이블의 다른 의미
- 입력으로 들어온 단어에 해당하는 행의 분산표현으로 연결해주는 역할
One hot encoding

단점
- 컴퓨터가 단어의 의미 또는 개념 차이를 전혀 담지 못한다
모든 벡터가 직교하기때문에(내적시 0) 이는 차원에서 서로 겹치지 않고 독립적으로만 존재한다는 것을 의미
임베딩 레이어에서 원-핫 인코딩의 사용 : 각 단어를 원-핫 인코딩해서 Linear 연산을 통해 임베딩 레이어 분산 행렬 읽어오기!
원-핫 인코딩을 위한 단어 사전을 구축하고 단어를 사전의 인덱스로 변환하여 임베딩 레이어 사용
입력으로 들어온 문자열 값은 숫자 인덱스로 변환되어 각 인덱스가 가르키는 임베딩 레이어의 분산표현을 나타냄
Tensorflow에서 Embedding 레이어를 선언하는 법
some_words = tf.constant([[3, 57, 35]])
# 3번 단어 / 57번 단어 / 35번 단어로 이루어진 한 문장입니다.
print("Embedding을 진행할 문장:", some_words.shape)
embedding_layer = tf.keras.layers.Embedding(input_dim=64, output_dim=100)
# 총 64개의 단어를 포함한 Embedding 레이어를 선언할 것이고,
# 각 단어는 100차원으로 분산 표현 할 것입니다.
print("Embedding된 문장:", embedding_layer(some_words).shape)
print("Embedding Layer의 Weight 형태:", embedding_layer.weights[0].shape)결과
Embedding을 진행할 문장: (1, 3)
Embedding된 문장: (1, 3, 100)
Embedding Layer의 Weight 형태: (64, 100)
주의사항
기본적으로 딥러닝은 미분을 기반으로 동작하는데, Embedding 레이어는 그저 단어를 대응 시켜 줄 뿐이니 미분이 불가능. 따라서 신경망 설계를 할 때, 어떤 연산 결과를 Embedding 레이어에 연결시키는 것은 불가능.
Embedding 레이어는 입력에 직접 연결되게 사용!
Recurrent 레이어
순차 데이터 - Sequential data : 시간을 축으로 앞 뒤 맥락과 내용적 연결성이 있는 데이터를 의미
ex) 자연어 문장, 영상데이터 등
Recurrent Neural Network - 순차 데이터를 처리하기 위해 고안된 딥러닝 모델
- RNN의 입력으로 들어가는 모든 단어만큼 Weight를 만드는 게 아님
- (입력의 차원, 출력의 차원)에 해당하는 단 하나의 Weight를 순차적으로 업데이트
- 한 문장을 읽고 처리하는 데에도 여러 번의 연산이 필요해 다른 레이어에 비해 느리다
기울기 소실(Vanishing Gradient) 문제 有

RNN code 작성 (keras)
sentence = "What time is it ?"
dic = {
"is": 0,
"it": 1,
"What": 2,
"time": 3,
"?": 4
}
print("RNN에 입력할 문장:", sentence)
sentence_tensor = tf.constant([[dic[word] for word in sentence.split()]])
print("Embedding을 위해 단어 매핑:", sentence_tensor.numpy())
print("입력 문장 데이터 형태:", sentence_tensor.shape)
embedding_layer = tf.keras.layers.Embedding(input_dim=len(dic), output_dim=100)
emb_out = embedding_layer(sentence_tensor)
print("\nEmbedding 결과:", emb_out.shape)
print("Embedding Layer의 Weight 형태:", embedding_layer.weights[0].shape)
rnn_seq_layer = \
tf.keras.layers.SimpleRNN(units=64, return_sequences=True, use_bias=False)
rnn_seq_out = rnn_seq_layer(emb_out)
print("\nRNN 결과 (모든 Step Output):", rnn_seq_out.shape)
print("RNN Layer의 Weight 형태:", rnn_seq_layer.weights[0].shape)
rnn_fin_layer = tf.keras.layers.SimpleRNN(units=64, use_bias=False)
rnn_fin_out = rnn_fin_layer(emb_out)
print("\nRNN 결과 (최종 Step Output):", rnn_fin_out.shape)
print("RNN Layer의 Weight 형태:", rnn_fin_layer.weights[0].shape)output
RNN에 입력할 문장: What time is it ?
Embedding을 위해 단어 매핑: [[2 3 0 1 4]]
입력 문장 데이터 형태: (1, 5)
Embedding 결과: (1, 5, 100)
Embedding Layer의 Weight 형태: (5, 100)
RNN 결과 (모든 Step Output): (1, 5, 64)
RNN Layer의 Weight 형태: (100, 64)
RNN 결과 (최종 Step Output): (1, 64)
RNN Layer의 Weight 형태: (100, 64)
return_sequences = 파라미터의 사용
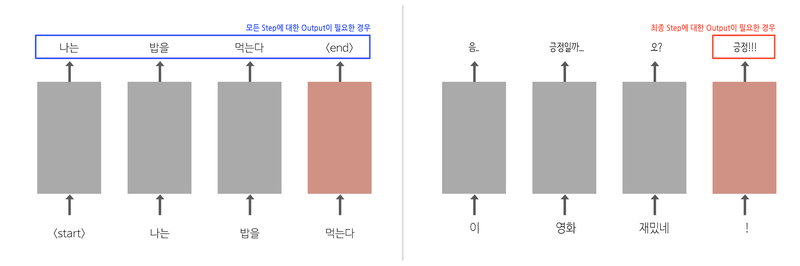
LSTM tensorflow code
lstm_seq_layer = tf.keras.layers.LSTM(units=64, return_sequences=True, use_bias=False)
lstm_seq_out = lstm_seq_layer(emb_out)
print("\nLSTM 결과 (모든 Step Output):", lstm_seq_out.shape)
print("LSTM Layer의 Weight 형태:", lstm_seq_layer.weights[0].shape)
lstm_fin_layer = tf.keras.layers.LSTM(units=64, use_bias=False)
lstm_fin_out = lstm_fin_layer(emb_out)
print("\nLSTM 결과 (최종 Step Output):", lstm_fin_out.shape)
print("LSTM Layer의 Weight 형태:", lstm_fin_layer.weights[0].shape)units = 64 : embedding vector의 차원 수 64(단어의 깊이)
결과
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
LSTM 결과 (모든 Step Output): (1, 5, 64)
LSTM Layer의 Weight 형태: (100, 256)
WARNING:tensorflow:Layer lstm_1 will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
LSTM 결과 (최종 Step Output): (1, 64)
LSTM Layer의 Weight 형태: (100, 256)
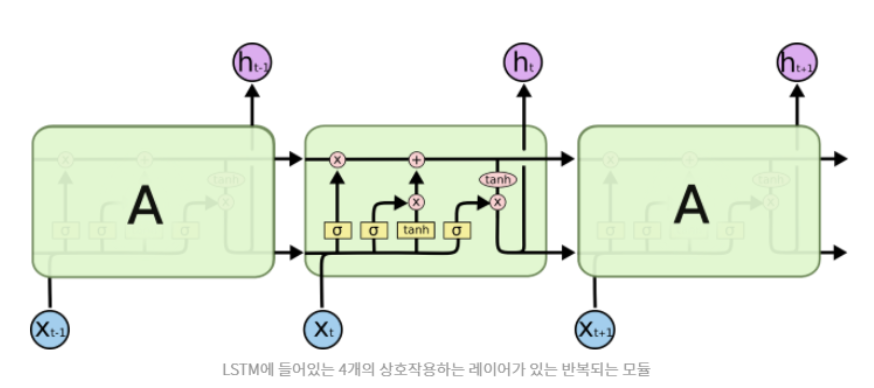
LSTM
구성
- Forget Gate Layer : cell state의 기존 정보를 얼마나 잊어버릴지를 결정하는 gate
- Input Gate Layer : 새롭게 만들어진 cell state를 기존 cell state에 얼마나 반영할지를 결정하는 gate
- Output Gate Layer : 새롭게 만들어진 cell state를 새로운 hidden state에 얼마나 반영할지를 결정하는 gate
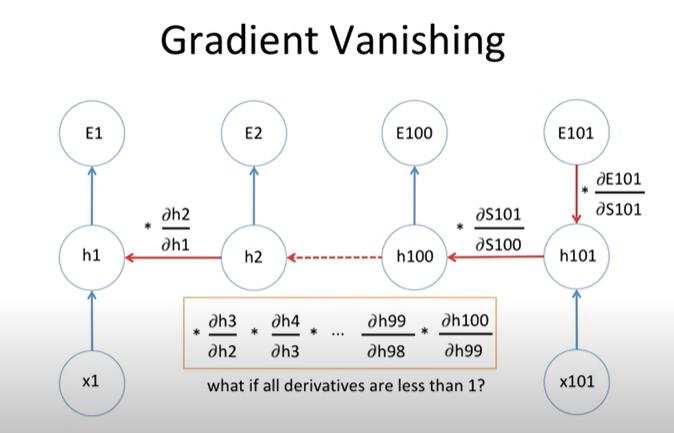
E101의 미분 값을 구하려면, 해당 그림과 같이 체인 룰을 이용한 역전파를 통해 구한다.
그러나 만약 |기울기| < 1 이라면? -> 곱셈이 반복되면서 기울기 값은 점점 줄어들 것이고, 그러면 깊은 층의 w들은 업데이팅이 거의 이루어지지 않을 것이다.
|기울기| > 1 이라면, 곱셈을 반복되며 기울기값이 매우 커지고, 이는 w값의 변동을 매우 크게 만든다 - gradient exploding 발생
- LSTM이 gradient vanishing에 강한 이유?
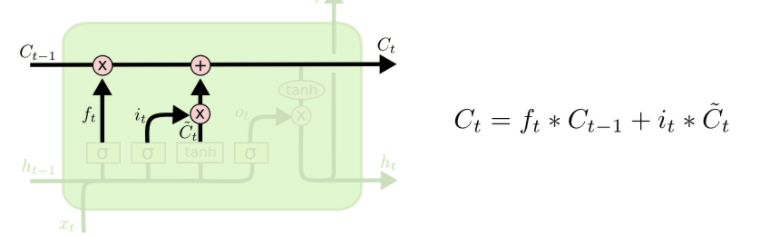
과거의 출력값 Ct-1은 f함수의 처리를 받는다. 이때 f는 sigmoid함수의 아웃풋이므로 0~1사이 값을 받게 된다.
즉, 확률값이라는 것이다. 이 값이 1에 가까운 값을 갖게 되면 과거 값의 미분값 소멸을 줄일 수 있다. 그리고 1 이상을 넘지 않기 때문에 exploding 될 확률도 없다.
( f값이 1에 가깝다? = 오래 기억할 만한 데이터라는 뜻 )
LSTM 더 많은 정보 + LSTM 변형 모델 참고자료
https://curt-park.github.io/2017-04-03/why-is-lstm-strong-on-gradient-vanishing/
LSTM가 gradient vanishing에 강한이유?
The reason why LSTM is strong on gradient vanishing
curt-park.github.io
양방향(Bidirectional) RNN
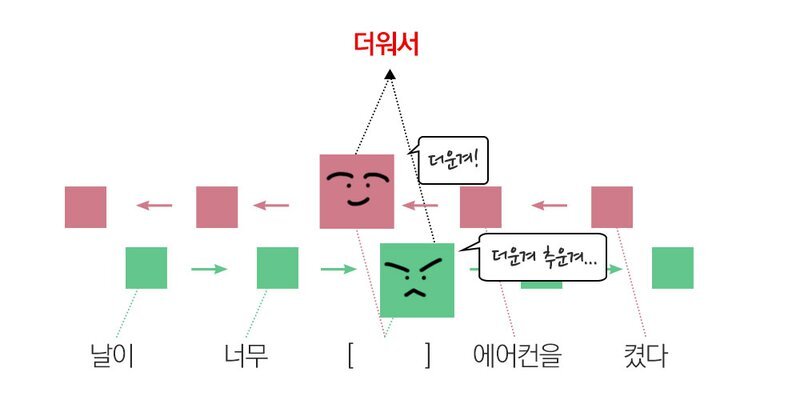
주로 번역에 사용 - 문장을 번역하려면 일단은 번역해야 할 문장 전체를 끝까지 분석한 후 번역을 시도하는 것이 훨씬 유리하기 때문
Tensorflow를 이용한 양방향 RNN code
import tensorflow as tf
sentence = "What time is it ?"
dic = {
"is": 0,
"it": 1,
"What": 2,
"time": 3,
"?": 4
}
sentence_tensor = tf.constant([[dic[word] for word in sentence.split()]])
embedding_layer = tf.keras.layers.Embedding(input_dim=len(dic), output_dim=100)
emb_out = embedding_layer(sentence_tensor)
print("입력 문장 데이터 형태:", emb_out.shape)
bi_rnn = \
tf.keras.layers.Bidirectional(
tf.keras.layers.SimpleRNN(units=64, use_bias=False, return_sequences=True)
)
bi_out = bi_rnn(emb_out)
print("Bidirectional RNN 결과 (최종 Step Output):", bi_out.shape)output
입력 문장 데이터 형태: (1, 5, 100)
Bidirectional RNN 결과 (최종 Step Output): (1, 5, 128)Bidirectional RNN은 순방향 Weight와 역방향 Weight를 각각 정의하므로 우리가 앞에서 배운 RNN의 2배 크기 Weight가 정의
units를 64로 정의, 입력은 Embedding을 포함하여 (1, 5, 100), 그리고 양방향에 대한 Weight를 거쳐
출력은 (1, 5, 128)
'Computer Technology 기록부 > 인공지능 학습 기록부' 카테고리의 다른 글
| Iris Data Classification Report(ENG) (0) | 2023.02.06 |
|---|---|
| Regularization과 Normalization (0) | 2022.02.11 |
| 딥러닝 레이어 이해하기 linear, Convolution (0) | 2022.02.08 |
| Deep network 종류 (0) | 2022.02.08 |
| CS231n Lecture 06. Training Neural Network (0) | 2022.02.07 |




댓글