첫 강의, 이미지 분류에 대해- A core task in CV
룰 베이스로 이미지 이해하기 - 불가능!


과거의 기계는 [둥근 머리에 세모난 귀 = 고양이] 등과 같은 룰 베이스로 이해했다. 그러나 이것은 실용적이지 못하다. 각도에 따라, 조명에따라, 그리고 위치나 자세에 따라 달라지는 고양이사진을 컴퓨터가 룰베이스로 이해할 수 없다.또 다른 객체(다른 고양이사진)를 인식해야한다면, 별도의 룰을 또 만들어야하는 문제 발생하기 때문.
-> 다양한 객체에 통용되는 유연한 알고리즘을 만들어야함!
해결방안 : Data-Driven Approach : Amount of Data set

인터넷에 있는 많은 양의 데이터 셋을 이용해 알고리즘을 학습시키자!
<필요사항>
- Train func : 알고리즘을 학습시키는 부분
- predict func : 실제 예측 함수부분

CIFAR10 data set : 머신러닝에 가장 많이 사용되는 이미지

- 학습데이터로 이미지 학습
- 테스트 데이터 이미지를 학습데이터 이미지셋과 비교
- 유사도가 가장 높은 것부터 정렬
- 가장 유사도 높은 사진(학습데이터이기 때문에 라벨 존재)의 라벨 파악
- 예측값 = 파악한 라벨 값
거리 척도 함수 - L1 distance
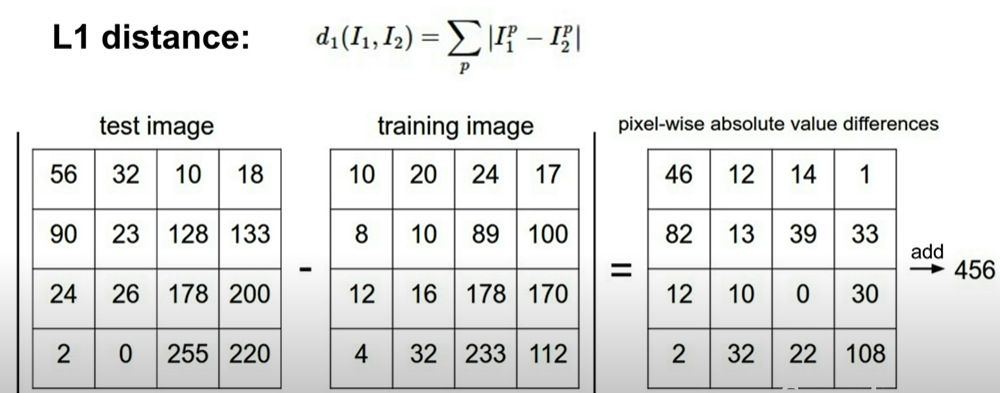
- 같은 위치의 픽셀값끼리 테스트데이터 - 학습데이터 를 한 뒤 모두 더해주면 차잇값 산출

파이썬으로 구현한 NN알고리즘 - 학습시간은 짧지만 실제 작동시간(예측시간)이 데이터 갯수에 따라 길어짐
(테스트 시 전체 학습 데이터 셋과 테스트 데이터를 하나하나 비교해야하기 때문이다)
K - Nearest Neighbors (NN 기법 + 인접 값들 중 최빈값의 라벨데이터)

예측값을 가장 가까운 하나의 라벨로 설정하는게 아니라, 주변 인접 라벨들의 최빈값으로 예측값을 결정함
k는 무엇인가?
- k는 몇번째 까지의 인접데이터를 투표에 사용할 것인지를 결정하는 기준 (그래서 홀수인가? 짝수면 동률 나올수도..)
- k = 1보다 높게 설정하는게 중요!
예측에 시간이 오래걸리고, 이상치가 많은 현실세계의 데이터를 다루는데는 k-nn가 부적절하므로 실제 이미지 분류에서는 잘 사용되지 않음
거리 척도 함수2 - L2 distance
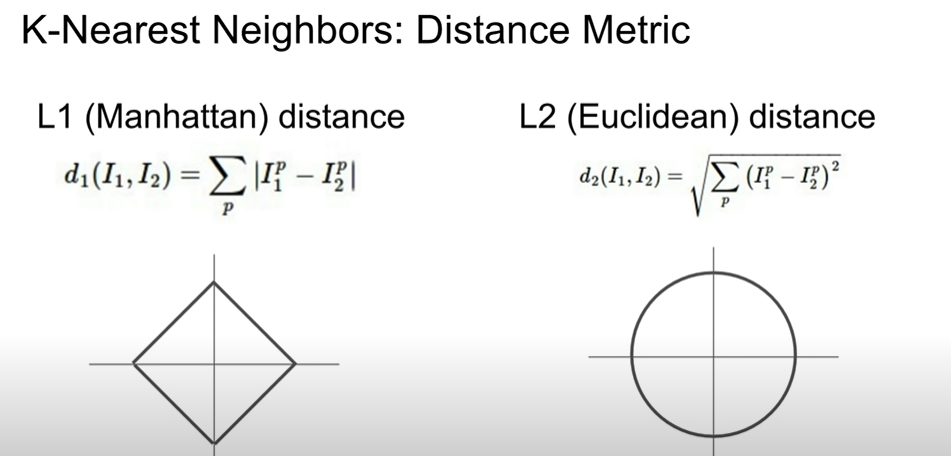
- L1 의 경우 어떤 좌표상에 있는지가 굉장히 중요 - 좌표 축이 바뀌면 L1거리도 바뀜 - 벡터의 각각 요소들이 개별적인 의미 가지고 있을떄 유용 (eg 키, 몸무게)
- L2의 경우 어떤 좌표계를 쓰는지나 축의 변형과는 상관 없음 - 벡터의 의미를 잘모르거나, 일반적인 벡터인 경우에 주로 사용
이러한 k나 distance matrix 처럼 문제에 따라 사용자가 직접 값을 정할 수 있는 것들을 hyperparameter 라고 한다.
Setting Hyperparameters
- Training data에 완벽히 작동하게끔 파라미터 설정하기 (BAD)
- 데이터를 Training data와 test data로 나눈 뒤, test data에 적합할 때까지 파라미터 설정하기 (BAD)
이유? : 머신러닝은, 한번도 보지 못한 데이터에서 성능을 보장해야한다. 그러나 test data set의 결과를 보고 다시 파라미터를 수정하면, test셋에만 오버피팅(과적합)되는 유연하지 못한 알고리즘이 될 수 있다. 따라서 다른 set이 필요하다
3. Training, Test, validation set으로 data를 나눈다. validation set은 학습에 관여하지는 않지만, 파라미터 수정에는 관여한다. 학습데이터로 모델을 학습시킨 뒤, validation 데이터로 정확도를 검증하며 파라미터를 수정한다. Test data는 마지막 검증에만 이용한다. (good)
아래는 validation set을 이용한 검증 방식중 하나인, 교차검증 과정이다.
각각의 경우에서 서로다른 부분에서 val 데이터를 추출하고 각각의 경우들의 평균을 구한다.

- validation data는 정답값(라벨)이 없다. test data도 마찬가지다.
K-nn이 실제로는 잘 사용되지 않는이유
- 1번 예측에 시간이 많이 할애됨 : 모든 학습데이터에 테스트데이터를 각각 비교해봐야함
- 유사도(거리) 기반으로 예측하는 모델인데, 만약 두 class간의 거리가 비슷하다면 예측 정확도 떨어짐 특히 L2 의 경우 이미지간 유사도를 측정하는데 효율적이지 못한 척도인데, k-nn은 L1이나 L2밖에 사용하지 못한다.
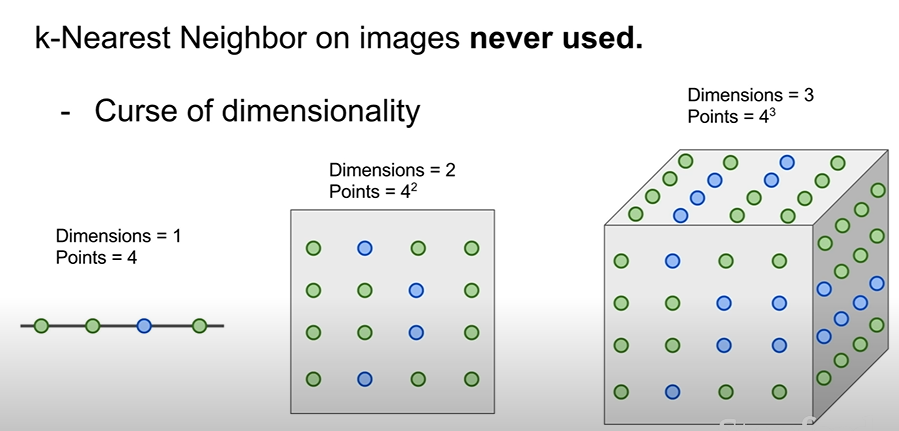
- 차원의 저주 - 데이터의 차원이 올라갈 떄 마다 전체 공간을 조밀하게 커버할 만큼의 충분한 트레이닝 샘플의 양이 기하급수적으로 증가
Linear Classification
parametric Approach
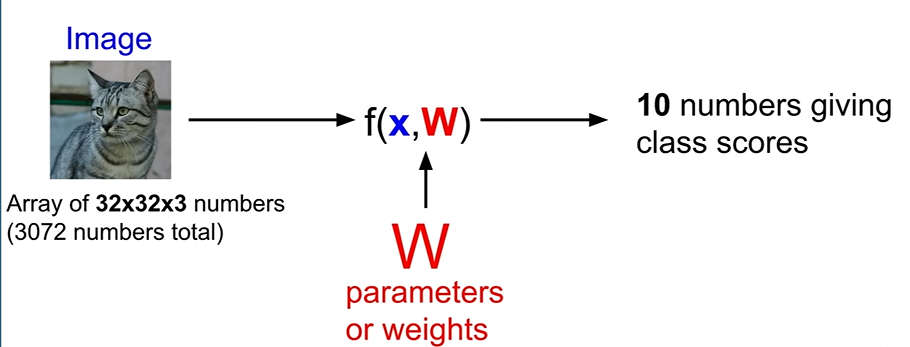
- image - x : input data
- f() : function - algorithm
- w : weights & parameters
- 10 numbers giving class score : It's because the classes of Dataset are 10EA
Purpose of Deep learinig : Set the function efficiently, and adjust parameters and weights properly.
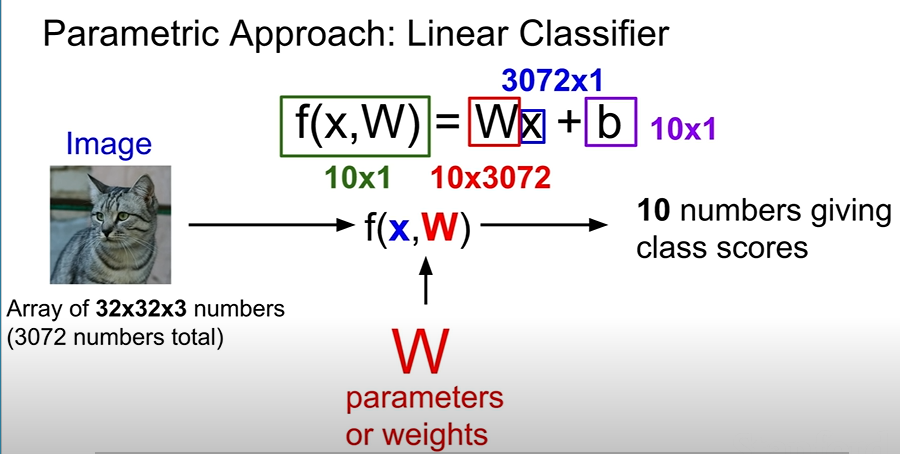
- Input Images = Array of 32x32x3(RGB) -> Stretch them all : 3072x1 column vector
- We want to end up with 10 classes score -> The Weight matrix size shuould be 10x3072 x
- w[10x3072] * x[3072 x 1] = y[10x1] ( ' * ' is dot product)
- Bias : 10x1 column vector -> Data independent, add with result, y. Give preperence to certain score
- for example, If cats data is more than dogs, then cats data gets more bias.
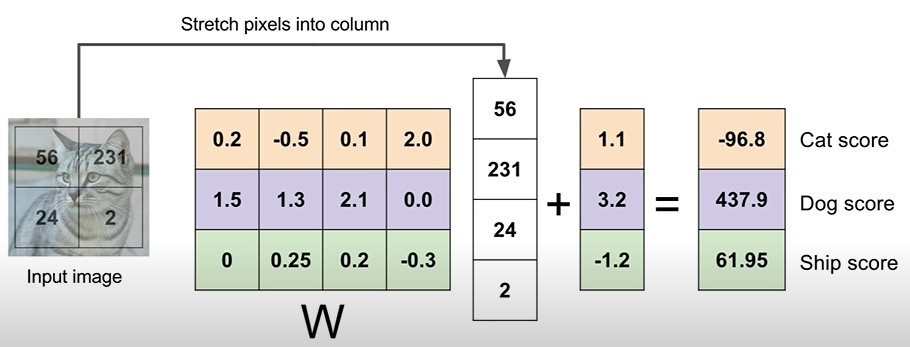
- Each row in matrix W, means tamplet of each image(class)
- Dot product with row vector of matrix W and column vector of matrix X
- The meaning of dot product - similar to measure tamplet-similarity between classes.
- Bias add scailing offsets in each class independently.
<Linear classifier Example in CIFA 10 data set>
how does each row actually work?

This blurred feature maps classify the class for input image
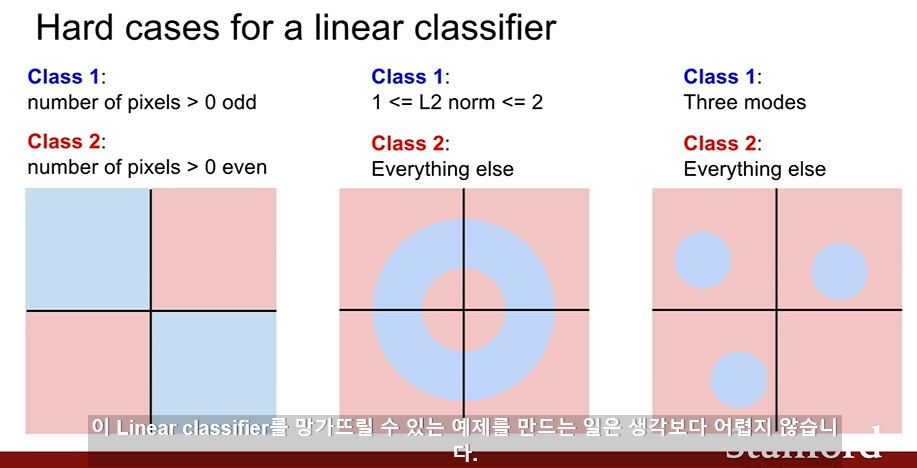
Limitations of Linear classifier
'Computer Technology 기록부 > 인공지능 학습 기록부' 카테고리의 다른 글
| CS231n Lecture 05. CNN - Convolution Neural Network (0) | 2022.02.06 |
|---|---|
| CS231n Lecture 04. Introduction to Neural Networks (0) | 2022.01.28 |
| 신경망(Neural Network)이란? (0) | 2022.01.25 |
| 딥러닝과 신경망의 본질 (0) | 2022.01.20 |
| CS231n lecture 03 Loss function and optimization (0) | 2022.01.17 |




댓글