딥러닝과 머신러닝의 차이는 무엇인지, 표현학습, 연결주의, 선형성은 무엇인지 알아보자
딥러닝vs머신러닝vs인공지능??

- 인공지능은 기계가 스스로 규칙 시스템을 만들어 학습하게 하는 과학을 말함(인간이 직접 프로그래밍x)
- 머신러닝은 데이터를 통해 스스로 학습하는 방법론을 의미. 데이터분석, 패턴학습, 판단/예측 실시
- 딥러닝은 머신러닝의 일종으로, 학습 모델의 형태가 신경망(NN)구조인 방법을 말함

- 기존의 머신러닝은 데이터를 입력하기 위해 사람이 feature를 가공해줘야 함 - 사람의 개입 많이 필요
- 딥러닝은 모델의 복잡성을 늘려 사람이 feature를 직접 가공하지 않아도 됨(자연어의 경우 embeding 필요)
딥러닝은 머신러닝과 달리 비정형데이터로부터 표현을 추출하는데 매우 능함
신경망(Neural Network)란 무엇인가?

Deep learning is inspired by neural networks of the brain to build learning machines which discover rich and useful internal representations, computed as a composition of learned features and functions.
뇌의 신경 구조로부터 영감을 받아 신경망 형태로 설계된 딥러닝의 목표는, "합성된 함수를 학습시켜서 풍부하면서도 유용한 '내재적 표현'을 찾아내는 machine을 구축하는 것"이다. - 조슈아 벤지오
- 여기서 내재적 표현이란
데이터의 특정 feature, pattern을 의미함.
데이터의 표현방식에서의 사람의 개입
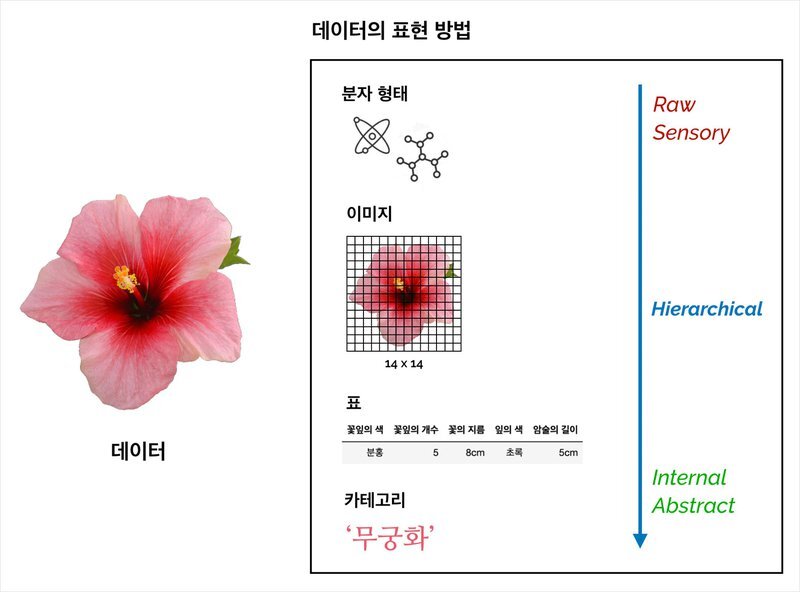
- 분자형태 : 실제 데이터형 - 사람의 개입x
- 이미지 픽셀값 형태 - 사람의 개입 少
- 표 형태 : 사람의 개입 필요(꽃잎의 색, 꽃잎 갯수 등 적절한 특징을 무엇으로 할 지 정해야함)
- 카테고리형태 : 사람의 개입 多 - 예측값으로도 사용됨. 각 데이터의 카테고리를 정해줘야하고, 전체 카테고리 집합도 만들어야함
딥러닝의 목표 : 학습된 함수를 사용해 유용한 표현(내재적 표현)을 뽑아내는 것
위의 추상적이고 내재적 표현(표나 카테고리 등)들을 사람의 개입 없이 딥러닝만으로 학습시키는 것이 목표

주로 이미지를 받으면, 내부 연산을 거쳐 최종적으로 한 줄로 펴진 숫자값으로 변환시킴 - 이미지의 특성/의미있는 표현들이 담긴 숫자들
- 데이터로부터 내재된 표현을 추출해낸다는것은 무엇인가?
- 추상적 표현을 추출한다는 뜻으로, 전체 데이터 안에서 이미지 전체를 추측할 수 있는 특징 벡터(픽셀값)를 뽑아내는 것을 의미한다.
딥러닝의 철학 : 연결주의(Connectionism)
- 행동주의 (자극 -> 반응)
- 심리학을 과학적으로 접근하고자하는 시도를 가진 분야, 철저한 경험적, 실증적 접근
- 인간의 지능 및 내면은 살아가면서 받는 자극으로 형성되는 후천적인 것으로 판단
- 무의식과 같은 관찰불가능한 것 배제
- 조작적 조건화 이론 : 생명체가 외부에서 받는 자극으로 인해 학습되는 과정
- 학습의 과정은 자극과 생존에 유리한 행동의 반복으로 이루어지는 것!
- 조작적 조건화 이론 : 생명체가 외부에서 받는 자극으로 인해 학습되는 과정

생명체가 자신에게 유리한 결과를 가져다주는 행동을 알게 된다면 그 행동의 빈도를 높인다는 '강화이론'은, 머신러닝의 방법론 중 '강화학습(Reinforcement Learning)'의 근간이 되는 이론. 강화학습은 실제로 특정 행위자를 학습시키기 위해 행위자가 하는 행동이 얼마나 좋았는지에 대한 척도인 '보상'을 부여하고, 행위자는 그 보상을 높이기 위해 자신의 행동을 교정하면서 학습.
- 행동주의의 한계
- 인간의 내면 지나치게 단순화함 - 단순히 이전에 받은 보상의 경험에만 행동하는 인간으로 간주
- 인간의 상상, 생각, 이해 등의 경험적 특징 설명 X
- 원시안적 사고로 현재 보상을 미루는 행위 설명 불가능
- 인지주의 (자극 -> 정보처리 -> 반응)
- 행동주의의 지나친 단순화에 반기를 들며 제기
- 단순히 자극에 따라 행동을 강화함으로써 학습하는 것이 아닌, 인간의 뇌에서 일련의 정보처리 과정을 거친 뒤 행동을 만들어낸다!
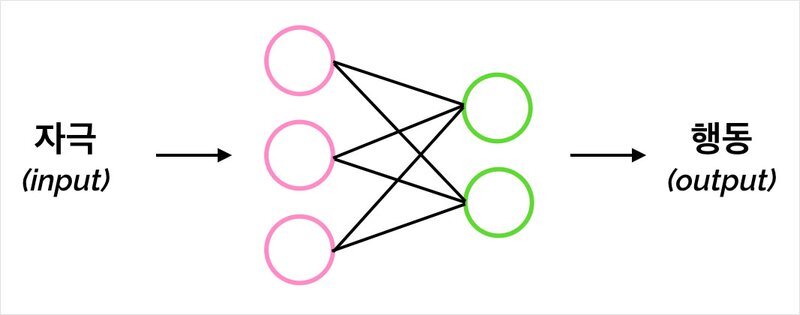
그렇다면 자극을 받아 반응하기까지 생명체 내부에서 정보가 어떻게 처리되는가?
어떻게 처리되기에, 인지, 사고, 상상, 등과 같은 '지능' 현상이 나타나는가?
- 연결주의(인지주의의 설명 방식 中 1.) - 정보처리는 뇌의 수많은 뉴런의 연결고리를 통해 이루어짐
- 인간의 지능을 자극과 반응의 관계로만 설명하던 행동주의 심리학에 반발하면서 등장한 설명방식
- 뉴런과 같이 연결되어있는 모형이 정보를 처리해 나간다고 설명
- 연결주의 관점에서의 지능체는 처음에는 백지상태 - 다수의 사례(데이터)를 주고 경험하며 스스로 학습
- 학습 내용은 뉴런 안 저장, 외부 자극에 따라 학습 내용 변경
딥러닝 - 연결주의에 기반한 머신러닝
- 뇌의 뉴런처럼 연결되어있는 모양을 본뜬 인공신경망을 모델로 가짐
- 자극(input)을 받아 내부에서 일련의 정보처리과정을 거쳐 반응(output)을 함
- 신경망 내부에서는 데이터를 여러 형태로 가공하며 표현하다, 최종단계에선 인간이 원하는 형테의 데이터 출력
신경망의 본질
딥러닝의 형태 - 함수!
- 딥러닝 알고리즘 : 데이터 입력 -> 정보처리 -> 출력의 형태 지님
- 함수 : 입력 -> 함수 -> 출력의 형태 지님


딥러닝의 정보처리과정은 인간의 뇌 연산을 모방한 거대하고 복잡한 함수!
함수의 역할
- 1. X,y의 관계를 나타내기
- y가 X의 함수다 = Y는 x의 변화에 종속적이다 / x의 변화에 따라 y값이 변한다.
- 2. x를 변환해 주는 도구(Transformation)
- 선형변환
https://www.youtube.com/watch?v=fNk_zzaMoSs&list=PLZHQObOWTQDPD3MizzM2xVFitgF8hE_ab
- 선형 변환 Linear Transformation은 행렬곱 연산과 연관되어있음
- 영상에서는 행렬곱 연산을 단순히 연산이 아닌, 선형 좌표계의 축 변환(공간 변환)으로 이해하고자 함
- 선형 변환이려면 공간 그리드 자체들은 직선으로 평행을 유지해야하고, 원점은 변경되지 아니해야 한다.
- 3. Mapping : x공간에서 y의 공간으로 mapping
- One-to-one 매핑
- many-to-one 매핑 - 주로 회귀문제에 자주 사용
- many-to-many 매핑 - 주로 분류문제에 자주 사용
입력값 키를 받으면 일정한 연산을 통해 몸무게 출력 : one-to-one 매핑

여러 정보를받아 하나의 값을 출력하는 경우 : many-to-one 매핑

여러 정보를 받아 여러 정보값을 출력 : many-to-many 매핑

함수 vs 모델
- 모델(model) : 데이터를 입력받아 원하는 값을 예측하거나 원하는 형태로 데이터를 표현해 출력하는 모든 함수

주로 우리가 모델에서 다루는 함수는 일차, 이차함수가 아닌 굉장히 고차항의 함수인 경우가 많다.
따라서 인풋값에 따른 정확한 아웃풋 값을 출력해 주는 완벽한 함수를 구할 수는 없고, 그나마 가장 잘 근사할 수 있는 함수를 만들어 예측값을 출력한다.
근사 함수 찾는 방법
- 1. 모델을 어떤 함수로 근사할 지 정하기 (Inductive Bias 또는 prior)
- Inductive Bias?
- 데이터를 설명할 수 있는 최적의 함수가 특정한 함수 공간에 존재할것이라는 가설
- 문제를 풀 때 알맞은 함수 형태로 모델을 선택하는 것이 중요하다. -> 해당 문제의 도메인 지식 필요!!!
- 입력데이터가 하나인 경우, 즉 one to one함수의 경우 일차함수를 사용
- 입력데이터가 여러개인 경우, 즉 Many-to-One 문제의 경우 다변수 선형함수로 정함
- 신경망 모델 이용하는 방법도 有 (비정형 데이터의 경우 계층구조인 신경망이 유리)
- Inductive Bias?
- 2. 정한 함수 모양 안에서 최적의 함수 찾기(학습)
- 딥러닝의 경우 학습을 위해 경사하강법 이용해 웨이트 조정
- 하이퍼파라미터 튜닝
딥러닝 인공신경망의 단위 블록, 퍼셉트론
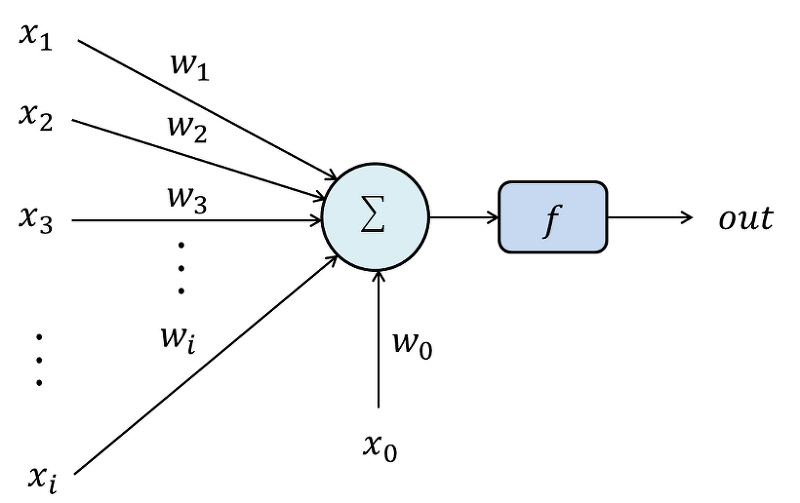
퍼셉트론(perceptron)
- 입력벡터를 받아 각 성분에 가중치를 곱하고, 그 결과를 합산한 뒤 활성화 함수를 적용해 출력값을 설정하는 하나의 함수
- 선형함수(가중치곱 후 전체합) + 비선형함수(활성화함수)의 조합
- 퍼셉트론을 여러 층으로 연결하는 것을 다층 퍼셉트론(MLP)이라고 한다.
딥러닝의 장점
- 효과적인 요인(특징, feature) 요약 추출의 자동화
- 원본 데이터로부터 최적의 성능을 발휘하는데 사용될 수 있는 특징들을 스스로 학습하고, 이를 기반으로 최적의 성능을 발휘하는 가중치를 더욱 효과적으로 찾기 가능 - 비정형 데이터도 손쉽게 처리 가능해짐
- 손쉽고 신속한 커스터마이징
- 더이상 사람이 특징 추출을 위한 룰을 짜주지 않아도 되기때문에, 업무가 상당히 간편해 짐.
딥러닝의 약점
- 많은 데이터 요구량
- 느린 속도와 높은 요구사항 - 높은 컴퓨터사양을 요하고, 학습에 오랜 시간이 걸림
딥러닝은 블랙박스인가? : 딥러닝의 연산 과정을 인간이 추적할 수 있는가?
- 결과의 신뢰성을 위해 연산 과정을 파악해 판단 및 예측 이유에 대해 설명하는 것이 반드시 필요함!
LIME library : Interpretable Machine Learning
예측 판단의 이유를 알려준다면 결과가 신뢰가능할것이다.
- LIME의 핵심 아이디어는 '입력값을 조금 바꿨을 때 모델의 예측값이 크게 바뀌면, 그 변수는 중요한 변수이다.'라는 것
- 즉, 이미지의 경우 이미지를 잘게 쪼개어 각 부분을 지운 상태로 넣었을 때 출력값이 크게 바뀌는지 아닌지를 확인하여 어떤 부분이 모델이 예측을 만들어 내는 데에 중요하게 작용했는지를 찾아낸다.
인공지능의 미래(review)
'Computer Technology 기록부 > 인공지능 학습 기록부' 카테고리의 다른 글
| CS231n Lecture 05. CNN - Convolution Neural Network (0) | 2022.02.06 |
|---|---|
| CS231n Lecture 04. Introduction to Neural Networks (0) | 2022.01.28 |
| 신경망(Neural Network)이란? (0) | 2022.01.25 |
| CS231n lecture 03 Loss function and optimization (0) | 2022.01.17 |
| CS231n Lecture 02 Image Classification (0) | 2022.01.11 |




댓글